文章列表: 3 篇
2025-10-31
2025-10-31 ~ 2026-02-25
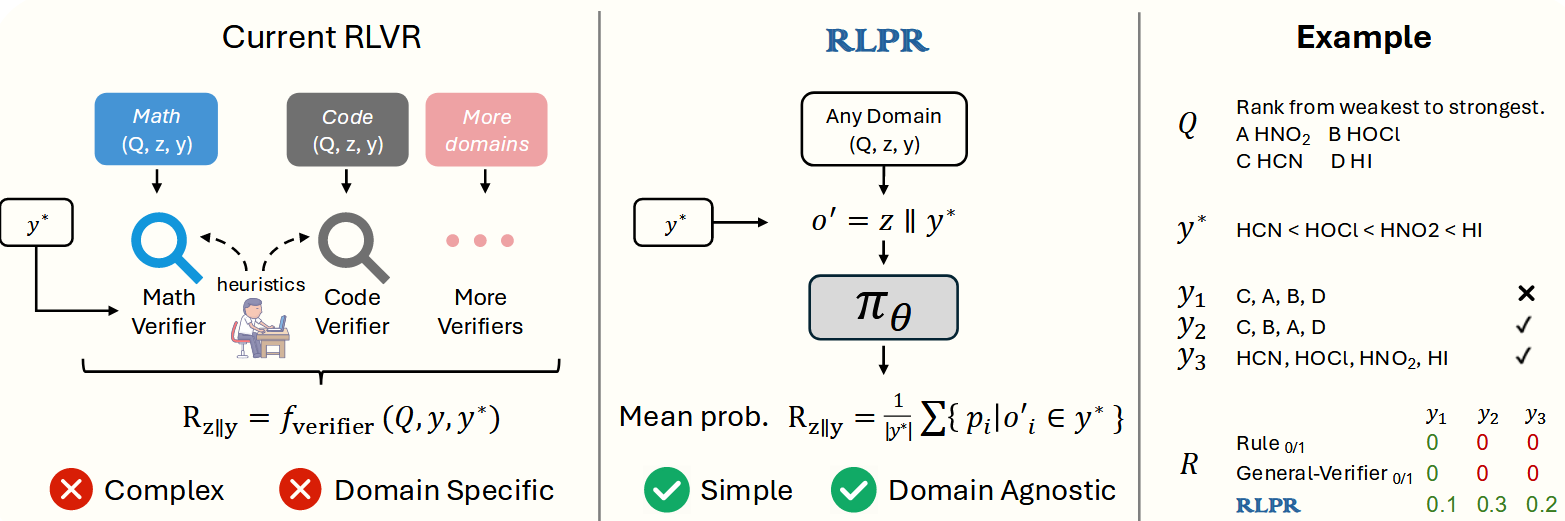
heuristic: 用于人工设计的规则,e.g., hand-crafted heuristic rewards
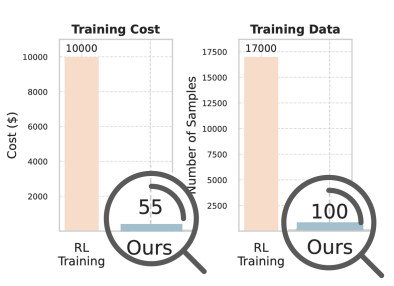
图表中数值差异过大怎么呈现? 用放大镜:

2025-10-29
2025-10-29 ~ 2026-02-25
这里记录我读的paper,或是整篇文章,或是文章中最有insight的部分。
25.10.10
- CARFT: Boosting LLM Reasoning via Contrastive Learning with Annotated Chain-of-Thought-based Reinforced Fine-Tuning
- 用embedding 做contrastive learning,作为ReFT(PPO)的regular loss
- disadvantage:实验的数据集较为简单
RL w/o verifier
RLPR: Extrapolating RLVR to General Domains without Verifiers 25.10.29