这里记录我读的paper,或是整篇文章,或是文章中最有insight的部分。
25.10.10
- CARFT: Boosting LLM Reasoning via Contrastive Learning with Annotated Chain-of-Thought-based Reinforced Fine-Tuning
- 用embedding 做contrastive learning,作为ReFT(PPO)的regular loss
- disadvantage:实验的数据集较为简单
RL w/o verifier
RLPR: Extrapolating RLVR to General Domains without Verifiers 25.10.29
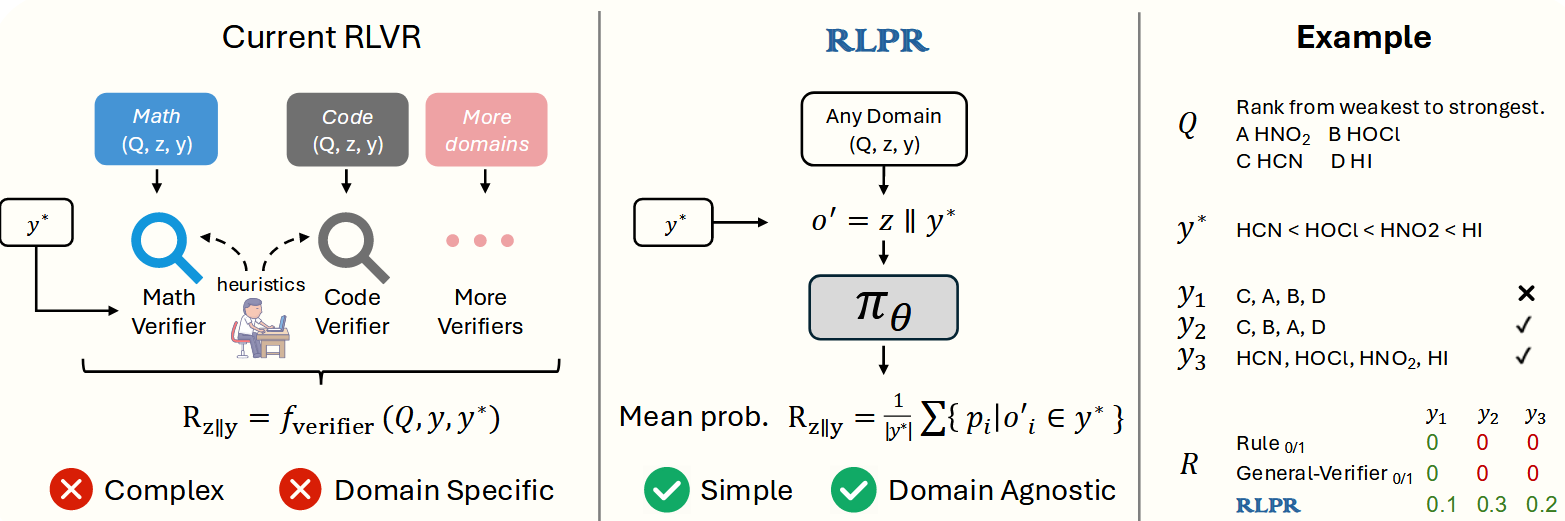
- 不使用verifier
- method: 将golden response中的final answer换为generated response的final answer,然后计算llm对于替换后的序列的generated response的final answer的decoding probability, 将这个probability作为reward.
- performance: 超过rule / model based verifier.
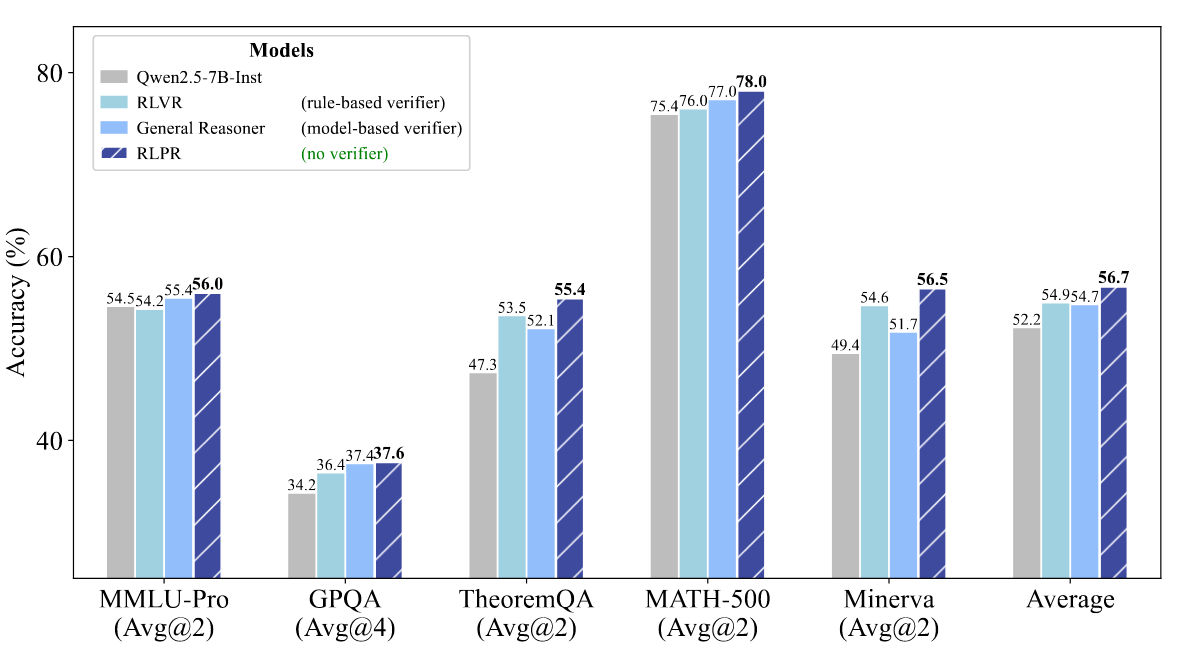
- disadvantage: 方法需要明确的final answer。但对于某些general task(e.g. abstract writing),整个generated response都是answer,没有final answer,这种难以应用。
Reinforcing General Reasoning without Verifiers
核心思想和RLPR一致,也是给定cot,把生成y*(正确答案)的概率作为优化目标。
Hidden state alignment
Token-Efficient Long-Term Interest Sketching and Internalized Reasoning for LLM-based Recommendation
- 对齐CoT和answer-only的
<answer>token, 这样得到的预测<answer> </answer>中的预测结果是一致的。
Beyond the Exploration-Exploitation Trade-off: A Hidden State Approach for LLM Reasoning in RLVR
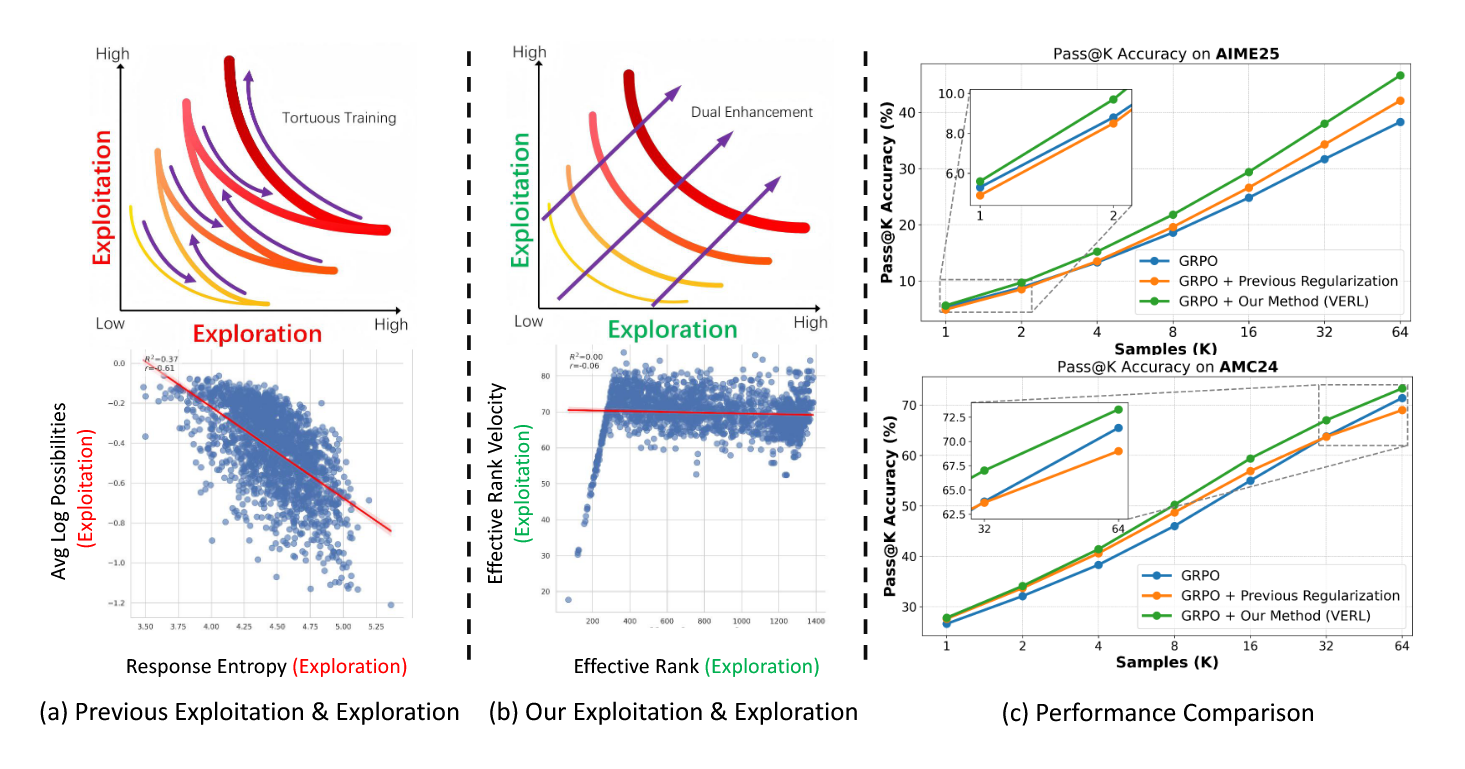
- LLM RL 过程中的 exploration和exploitation 的trade off只是一种token level上的假像,本文通过研究hidden state的E-Rank 和 ERV (first order of erank) 和ERA (second order of erank)发现exploration和exploitation可以同时优化。并利用E-Rank,ERV,ERA提出了辅助优化目标。